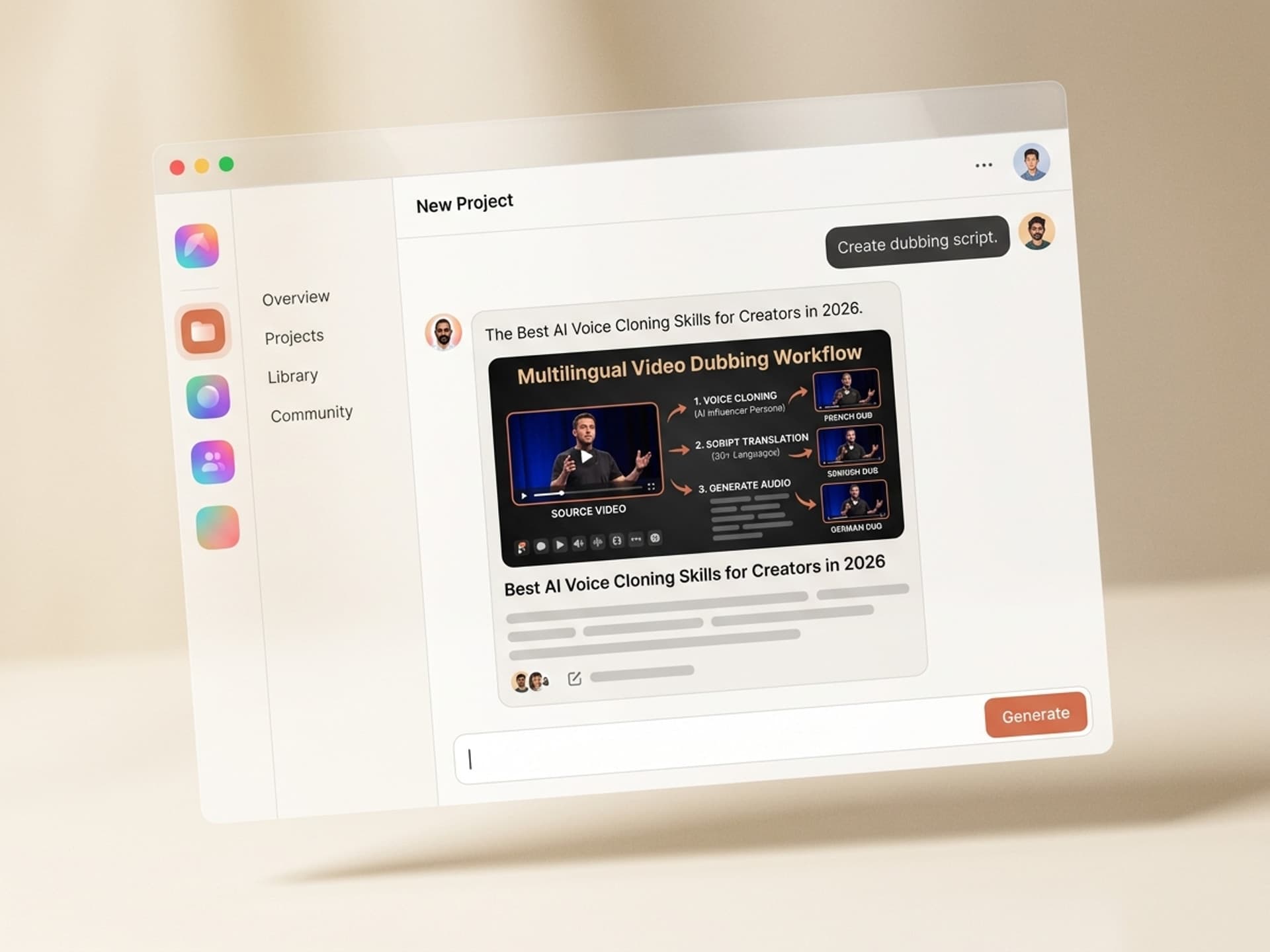
2026 年创作者的最佳 AI 声音克隆技能
AI 声音克隆让创作者能够使用自己声音的 30 秒样本,发布 30 多种语言的内容,每天发布 AI 角色内容,并将播客变成 24/7 的生产线。 ElevenLabs 在商业市场处于领先地位,延迟不到一秒,支持 70 多种语言,但围绕它的工作流程(素材库设置、配音、品牌声音一致性、道德披露)分散在五种工具中。AI 声音克隆技能将整个流程打包成一次安装,让创作者不必费力连接工具,而是可以专注于内容发布。最快的入门方式是直接从 Vibe Skills 获取现成的声音技能。
这是一本创作者的操作手册,而不是工具的汇总。真实的播客主播、YouTube 博主和 AI 角色创作者正在使用声音克隆技术,在无需聘请录音棚的情况下,用更多语言发布更多内容 - - “早期采用者”与“所有人都在使用”之间的差距正在迅速缩小。
为什么声音是 AI 角色增长的瓶颈
对于大多数创作者而言,AI 内容的视觉部分已经解决了。图像和视频模型在 2025 年达到了照片级写实质量。但声音才是让一个角色感觉真实的关键 - - 而声音恰恰是工作流程中断的地方。
瓶颈体现在三个方面:
- 制作速度。 考虑到设置、重录和编辑的时间,录制 20 分钟的纯净旁白需要 60 - 90 分钟的录音棚时间。如果每天都要制作 Shorts,那这一个星期就废了。
- 语言覆盖范围。 只会说英语的创作者,其潜在受众规模(TAM)大约为 15 亿人。如果用 10 种语言进行配音,这个数字将跃升至超过 50 亿的潜在观众。自 2024 年底以来,YouTube 一直大力推广多语言音频轨道 - - MrBeast 的配音频道总观看量超过了他的英语频道。
- 角色一致性。 AI 角色需要一种声音,无论是在周二还是三个月后,听起来都一样。为每日 AI 角色聘请配音演员,每次会话费用为 300 - 800 美元,一旦他们生病或提高费率,就无法保证持续性。
ElevenLabs 报告称,仅在 2024 年,其平台就克隆了 250 万个声音。预计到 2032 年,市场规模将达到 54 亿美元,年复合增长率(CAGR)为 26%。原因很简单:声音克隆将音频制作成本从“录音棚会话”降低到“API 调用”,同时在盲测中,其输出与人类的声音几乎无法区分。
所缺失的是模型之上的工作流程层 - - 而这正是 AI 技能发挥作用的地方。
创作者的声音克隆使用场景
声音克隆不是一项单一功能。它是一系列使用场景的集合,当它们组合在一起时,价值会成倍增长。以下是创作者在 2026 年实际获得报酬的方式:
| 使用场景 | 取代的是 | 节省时间 |
|---|---|---|
| 多语言视频配音 | 每种语言每小时 2,000 - 5,000 美元的人工录音棚费用 | 在 30 分钟内将 10 分钟的视频翻译并配音成 8 种语言 |
| AI 角色旁白 | 每场 300 - 800 美元的配音演员费用,每日内容每年 3 万美元以上 | 一个下午即可发布 30 天的 AI 角色 Reels |
| 播客助手声音 | 第二位主持人或制作人(每年 5 万美元以上) | 按需生成片头、片尾、广告读稿和节目片段过渡 |
| 有声读物 + 课程旁白 | 每成品小时 200 - 400 美元的自由职业旁白员费用 | 一次性批量渲染 6 小时的课程旁白 |
| 新闻通讯音频版本 | 完全跳过音频(大多数创作者的做法) | 为每篇新闻通讯自动生成播客 Feed |
| 直播活动个性化 | 通用的预录语音邮件 | 用你自己的声音向 1,000 名与会者发送个性化音频消息 |
从第二个使用场景开始,经济效益发生转变。仅做配音的创作者可以快速收回成本。而使用同一声音素材库进行配音 + 角色 + 播客 + 课程旁白的创作者,可以在一个 Shorts 发布周期内收回整个 AI 堆栈的成本。
问题在于操作层面,而非技术层面。大多数创作者尝试手动连接 ElevenLabs + 翻译工具 + 视频编辑器 + 播客平台 - - 两周后就放弃了。AI 技能解决了这个问题。
2026 年声音克隆工具格局
快速了解底层工具,以便理解技能推荐的合理性。创作者无需学习所有这些工具 - - 技能已经将它们封装起来。
| 工具 | 最适合 | 语言 | 声音克隆质量 |
|---|---|---|---|
| ElevenLabs | 最高保真度,播客和角色内容 | 70+ | 行业领导者。30 秒内即时克隆,30 分钟内专业克隆 |
| Descript Overdub | 编辑现有录音,播客清理 | 以英语为主 | 适合修复,整体生成效果稍弱 |
| OpenAI Voice Engine | 对话式 AI,长篇回复 | 50+ | 高质量,访问受限(等候名单) |
| Google Vertex AI / Chirp | 企业配音,YouTube 自动配音 | 100+ | 在口音转移方面表现出色,在情感细微差别方面稍弱 |
| Resemble AI | 实时声音克隆,游戏,NPC | 60+ | 强大的实时 API,用于交互式产品 |
ElevenLabs 是 2026 年创作者的首选。 它在 2025 年实现了低于 300 毫秒的延迟,支持 30 秒样本的声音克隆,并且现在提供原生的多语言配音,可以在不同语言中保留说话者的声音。市场上大多数 AI 声音克隆技能都使用 ElevenLabs 作为主要引擎,并在此基础上添加工作流程层。
Vibe Skills 上的 5 个 AI 声音克隆技能
每一个都是一个打包的工作流程 - - 不仅仅是一个设置清单。安装一个,上传你的声音样本,然后发布。
| 技能 | 最适合 | 包括内容 |
|---|---|---|
| 多语言视频配音器 | YouTube 博主、课程创作者、社交视频 | 自动检测源语言,翻译,以你的克隆声音生成 30 多个目标语言的配音轨道,可选唇语同步 |
| AI 角色旁白套装 | AI 影响者创作者、虚拟模特创作者 | 完整的素材库设置、品牌声音规则、片头/片尾/吸引点模板、内容节奏预设 |
| 播客 AI 联合主持人 | 播客主播、新闻通讯音频创作者 | 克隆声音 + 内容简介输入,生成广告读稿、节目片段过渡、节目摘要、社交媒体引语 |
| 有声读物 + 课程旁白 | 课程创作者、独立作者、教育工作者 | 对长篇剧本进行批量旁白,具有一致的语速、章节分隔检测、技术术语发音库 |
| 声音身份工具包 | 单独创作者、自由职业者、创始人 | 设置克隆声音 + 品牌声音规则 + 50 个可重用音频片段(CTA、片头、语音邮件、社交媒体吸引点) |
所有这五种技能都位于 Vibe Skills 的 AI 影响者类别 中,旁边还有完整的身份工具包(面部、声音、内容支柱)。订阅者可以安装无限技能 - - 因此大多数创作者会为他们的角色叠加 2-3 个这样的技能。
30 分钟克隆你的声音(分步操作)
这是实际的工作流程。首次端到端完成,包括道德设置,不到 30 分钟。
步骤 1:在 Vibe Skills 上选择合适的技能
打开 AI 影响者类别,选择符合你使用场景的工作流程(如果你从零开始,选择声音身份工具包;如果你已经发布视频,选择多语言视频配音器),然后安装它。每个技能都附带一个设置清单、一个 ElevenLabs 配置和一个品牌声音模板。
步骤 2:录制你的声音样本
你需要 30 秒的纯净音频才能快速克隆,或者 30 分钟才能进行专业克隆。在安静的房间里用 USB 麦克风录制(79 美元的 Samson Q2U 就足够了)。自然发声 - - 朗读一段文字,讲一个 90 秒的故事,然后录制 5 种不同的情感读音(兴奋、平静、严肃、友好、好奇)。
步骤 3:上传 + 训练声音
该技能会引导你完成 ElevenLabs 的声音创建过程:即时克隆以快速获得结果,专业克隆以获得最高保真度。训练时间从 30 秒(即时)到几小时(专业)不等。清晰地命名你的声音 - - “Elena Brand Voice 2026” - - 以便你的素材库保持井然有序。
步骤 4:设置品牌声音规则
这是每个创作者都会跳过、又都后悔的步骤。在技能内部,填写品牌声音规范:语速(慢/自然/精力充沛)、语气(温暖、权威、俏皮)、允许或禁止的填充词、产品名称的发音规则。该技能会保存这些规则并应用于每一次渲染。
步骤 5:生成你的第一个内容
从技能中选择格式:配音视频轨道、播客片头、AI 角色 Reels 脚本、课程章节旁白。粘贴你的文本,点击渲染,几秒钟内即可获得音频文件。大多数技能直接导出为 MP3、WAV 或带有新音频轨道的视频文件。
步骤 6:添加披露声明
对于任何观众可能误将 AI 声音视为人类的输出,请添加披露声明。该技能附带披露模板(“此音频使用了创作者的 AI 声音克隆”),并建议放置位置(视频描述、播客节目说明、社交媒体标题)。这并非可选项 - - 请参阅下面的道德部分。
步骤 7:发布 + 重用
将渲染的文件保存到你的素材库。该技能会维护一个版本历史记录,以便你可以用新的语言重新渲染相同的脚本,更换声音,或者更新脚本而不会丢失声音设置。大多数创作者会在 Notion 或 Frame.io 中设置一个“声音素材库”,并在每次活动中从中调用。
道德、同意和披露(每个人都跳过的那部分)
声音克隆是目前 AI 中最具道德争议的类别。三个规则可以让你避免麻烦 - - 并站在平台政策、监管机构和你的观众的正确一边。
只克隆你自己的声音。 或者获得你克隆的声音所有者的明确书面同意。FTC 在 2024 年因非自愿声音克隆而对一家 AI 声音服务制造商处以 2500 万美元的罚款。欧盟《人工智能法案》将非自愿声音克隆归类为高风险系统。你的播客嘉宾、你的同事、你最喜欢的 YouTuber - - 没有他们的签名许可,你都不能随便使用他们的声音。
披露 AI 生成的音频。 在视频描述、播客节目说明或社交媒体标题中添加清晰的注释(“创作者的 AI 声音克隆”)。YouTube 的负责任 AI 标签规则于 2024年生效,适用于任何可能被误认为是真人的合成声音。Meta 和 TikTok 现在会自动检测并标记 AI 音频 - - 但自己去做比让平台代劳更具可信度。
切勿冒充真人 - - 尤其是公众人物。 克隆政客、名人或任何真实第三方用于讽刺、广告或角色内容,将很快导致内容被下架、诽谤诉讼或更糟糕的后果。2024 年 FCC 的裁决规定,在美国,使用克隆政治声音的 AI 生成的自动电话是非法的。切勿尝试。
好消息是:Vibe Skills 上每一个合法的声音克隆技能,都将同意验证、披露模板和平台政策合规性融入了工作流程。这也是你付费的一部分。
常见问题解答
AI 声音克隆对创作者合法吗?
是的 - - 只要你只克隆你自己的声音,或者获得声音所有者的书面同意。在大多数司法管辖区,未经同意克隆公众人物或第三方是非法的,并且违反了所有主要平台的服务条款。Vibe Skills 上的技能提供同意模板和披露指南,以确保你合规。
2026 年 AI 声音克隆质量与人类相比如何?
ElevenLabs 和 Vertex AI Chirp 提供的顶级声音克隆,在短格式音频的盲测中,其不可区分性超过 80%。对于长格式(30 分钟以上不间断)而言,人类旁白在情感细微差别和气息控制方面仍然略占优势 - - 但差距每季度都在缩小。对于大多数创作者的使用场景(Reels、Shorts、播客片头、配音),AI 的质量已经足够好,观众几乎察觉不到。
我可以用声音克隆来制作播客吗?
是的,这是投资回报率最高的使用场景之一。你可以使用克隆的声音来制作广告读稿、节目片头、片尾、片段过渡和引述 - - 而将你真实的声音用于主要访谈内容。一些创作者使用完整的 AI 联合主持人。Vibe Skills 上的播客 AI 联合主持人技能负责整个流程:声音克隆、简介输入、自动片段生成以及直接导出到你的播客主机。
运行一个声音克隆工作流程需要多少成本?
ElevenLabs 的定价从个人用户的 5 美元/月开始,到专业创作者(大多数职业创作者使用)的 99 美元/月。Vibe Skills 的专业版订阅费用为 39 美元/月,包括无限的声音克隆技能以及其他所有内容。一个专业创作者的总堆栈成本:每月低于 150 美元。与一次 2,000 美元以上的自由职业配音会话相比,这笔账非常划算。
我的观众会在意我使用 AI 声音吗?
如果工作流程设置得当,大多数人不会注意到。观众关心的主要有三点,按顺序排列:内容是否好,创作者是否真实,是否有披露声明。清晰地披露 AI 声音可以保持信任。如果隐藏它,一旦被发现 - - 而他们一定会发现 - - 你就会失去观众。2025 年的研究发现,观众惩罚隐藏 AI 使用的力度是披露 AI 使用的 3 倍。
声音克隆和 AI 语音播报有什么区别?
AI 语音播报使用来自素材库的预设声音(ElevenLabs、OpenAI TTS、Google Cloud TTS)。声音克隆则从样本生成你自己的声音(或获得同意者的声音)的音频。就品牌一致性而言,声音克隆胜出。对于一次性的通用旁白,预设 AI 语音播报也可以,并且成本略低。
我能用我自己的声音把我的 YouTube 视频配音成其他语言吗?
是的 - - 这是 2026 年排名第一的使用场景。Vibe Skills 上的多语言视频配音器技能可以接收你的源视频,转录音频,将其翻译成你的目标语言,并以你的克隆声音生成 30 多种语言的配音轨道。YouTube 的多语言音频功能允许你将所有音轨上传到同一个视频,这样每个观众都会自动听到他们自己的语言。
底线:声音是新的分发渠道
在 2026 年,任何不使用声音克隆技术的创作者,都将错失一个重要的分发渠道。多语言覆盖、每日 AI 角色内容、播客扩展、课程旁白 - - 这些不再是实验性的。它们是严肃创作者的基准。
正确的做法不是学习五个工具并将它们连接起来。而是安装一个封装了工作流程的技能,上传你的声音样本,然后开始发布。Vibe Skills 上的 AI 声音克隆技能负责 ElevenLabs 的设置、品牌声音规则、配音流程、披露模板和导出格式 - - 这样你就能保持创作者的身份,而不是操作员的身份。
在 Vibe Skills 上浏览声音克隆 + AI 角色技能 →
跳过录音棚。用你的声音,用所有语言发布。在 Vibe Skills 上安装 AI 声音克隆技能。